




You might have heard the name Kubernetes or K8s already and can't really imagine what it is, or you've already heard about it but still need a little more information.
No matter what your background is, as long as you're interested, this article is for you.
However, this article does not have the goal to give you an in-depth insight into Kubernetes. Take it as a high-level overview, that scratches some surfaces here and there, and which wants to give you a general idea of Kubernetes.
What is Kubernetes?
Kubernetes is an open source container orchestration platform. It basically handles everything related to deploying, managing and scaling containerized applications. Its name originates from Greek, meaning something like pilot.
You might have already worked with Docker and created a few containers, started them, and then used it to deploy a database to test your app locally. And now imagine that you want to take your app, containerize it, and deploy it to a server. But instead of only one instance, you want to deploy three instances on three different machines.
This seems a little more difficult, doesn't it?
And how should other applications reach your app? Should they really know about all three containers with different IP addresses? Well, most certainly not, so you need a load balancer or reverse proxy that takes incoming traffic and distributes it across your three instances. But this leads to another problem. Every time you add a new instance, you need to add it to your proxy's configuration!
Okay, that's only one app you need to do all the work for. Multiply that by 10, 20, or 35 and you have a small system running at scale. That would be a lot of manual work, scaling services, configuring proxies, and somehow documenting what runs where and how.
Kubernetes was designed and developed by Google to tackle exactly those problems. To be more precise, Google first developed Borg to tackle those problems, which ultimately lead to the development of Kubernetes as a successor to Borg.
Google later open-sourced Kubernetes and finally gave it over to the Cloud Native Computing Foundation as a seed technology which now manages its further development.
How does Kubernetes work?
Kubernetes is a cluster application that runs distributed on many machines.
While Docker is there to handle containers, Kubernetes is the orchestrator, that uses a container runtime like containerd to manage containers running on multiple servers.
By the way: containerd is the container runtime also used by Docker under the hood. Kubernetes recently deprecated Docker as a runtime in favor of OCI-compliant runtimes like containerd.
General Architecture Of Kubernetes
You can take a look at the image below to get an idea of the general architecture of Kubernetes.
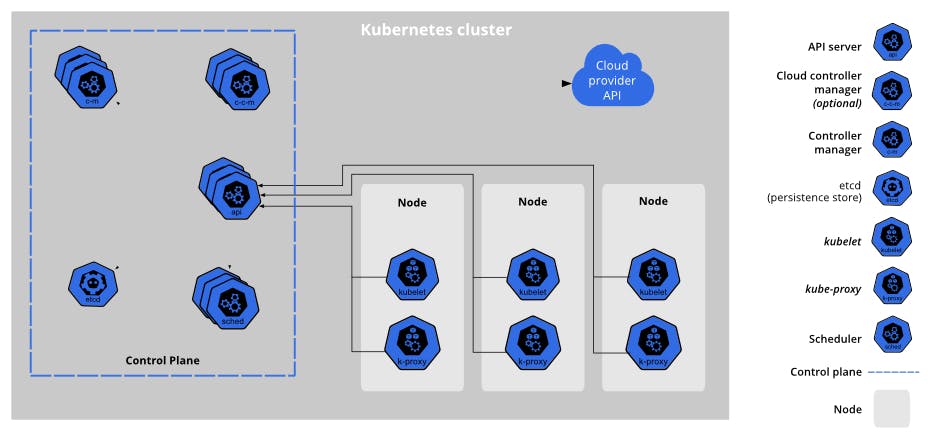
As you can see, Kubernetes is designed as a distributed system.
There are Control Plane components that can run on one or on multiple machines. They are the cockpit and make all decisions regarding the whole cluster (like scheduling).
And then there are nodes which contain the components necessary to handle user containers. And we'll take a closer look at those components now.
Kube-Proxy
A kube-proxy is a component that handles everything related to the network. It basically builds the cluster network and makes that containers, respectively Pods, can talk to each other on different machines. It either uses the operation system's packet filtering layer, if available, or forwards the traffic itself.
Kubelet
A kubelet is a container and Pod management component. It handles the complete lifecycle of containers and uses the underlying container runtime for that task. It's like a robot copy of you using the Docker API to start and stop containers.
Every time you tell Kubernetes to deploy some Pod, the control plane components schedule the Pod and thus its containers, and then tell the appropriate kubelet to take over and get all related containers running.
The kubelet then calls the underlying container runtime and sends the commands you would usually send by using the Docker CLI, for example. But instead of using the CLI (like you would most probably do), it connects to the REST API and sends its commands over HTTP.
It is also responsible to check if the container is still running and restart it if it becomes necessary.
Controlling Kubernetes
If you still remember the image showing Kubernetes' architecture, you might remember that there is an API component located within the control plane components.
Like Docker offering a REST API, Kubernetes does so, as well.
If you want to communicate with the cluster, the API is the way to do so. You could use curl to send requests to the cluster, and use this documentation to find out about all endpoints offered and each associated request.
But another and most probably better way as a user is to use kubectl, which is a CLI tool that sends requests to the Kubernetes API under the hood. You can read more about it here.
No matter which way you use to communicate with and control the cluster, you'll work a lot with YAML files. Because how you work with Kubernetes is pretty special. Instead of you telling it exactly what to do, you define a desired state and let Kubernetes decide how to get there.
An Example Spec
You can take a look at the following spec of a Deployment to get a general idea of that "define what you want and let Kubernetes decide how to get there" thing.
It tells Kubernetes that you want three instances of an nginx container, reachable on port 80. If you hand over this spec to Kubernetes, its components will decide how to best reach that goal.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Oh and did you notice this field 'kind' within the yaml spec? That's another awesome thing that Kubernetes offers. It is extendable!
Many of Kubernetes' core components are actually implemented, including custom resource definitions, which define their own version and kind. Components within the cluster can react when a yaml spec with a kind, associated with a custom resource definition, is sent and do their work based on what is written within this spec.
What's Next
You've got a pretty high-level overview of Kubernetes in this article. Nothing too deep, and hopefully just enough to help you understanding what this container orchestrator is basically all about.
If you want to learn more about Kubernetes, there are a lot of great resources out there on the internet.
The Official Documentation
It's not always obvious, but the official Kubernetes documentation is an awesome place to learn everything about everything that Kubernetes has to offer.
You can find it here
Katacoda
Katacoda is an offer by O'Reilly. It contains interactive lessons which you can complete from within your browser. No need to install a cluster locally or in the cloud to play around with Kubernetes!
You can find it here
Introduction To Kubernetes
This one is a course offered by the Linux Foundation itself (which is basically the roof foundation of the Cloud Native Computing Foundation), so they are pretty closely related to Kubernetes.
You can find it here
Conclusion
That's it for this article which hopefully gave you a pretty high-level overview of Kubernetes. Perhaps it even motivated you to take a deeper look into the world of Kubernetes. And if so, I hope that you'll enjoy the wonderful world of Kubernetes and its large ecosystem of the cloud native landscape.
No matter what you take with you from this article, don't be afraid of Kubernetes. It may seem pretty complex first, but as soon as you deployed your first few applications, it becomes pretty straight-forward to use. At least as a developer.
Before you leave
If you like my content, visit me on Twitter, and perhaps you’ll like what you see!