




If you ever read at least a little about Kubernetes or followed a simple tutorial, you must have come across the term "Pod".
In case you're still wondering what it is, this article is for you.
What is it?
A Pod is the smallest deployable unit in Kubernetes. It's a group of one or more containers that form a logical host. They share their storage, their network, and are always co-located and co-scheduled.
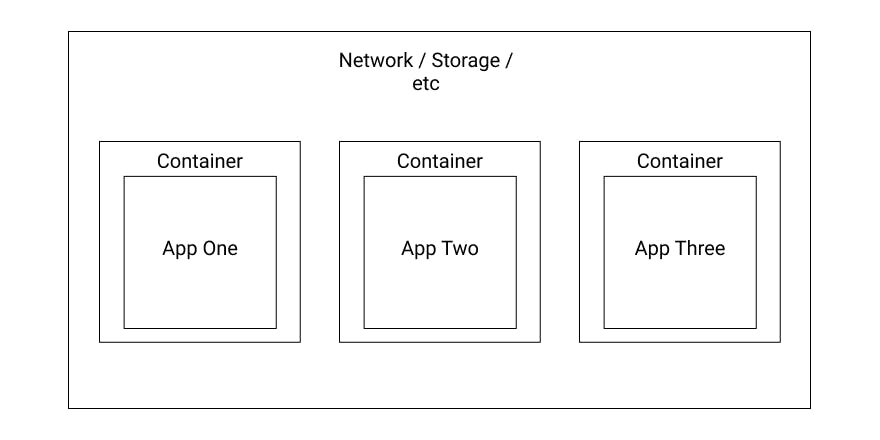
The most common use case is a Pod with exactly one container. Multiple containers within a Pod are usually a pretty advanced use-case. So, naively spoken, a Pod is often only a wrapper around one container.
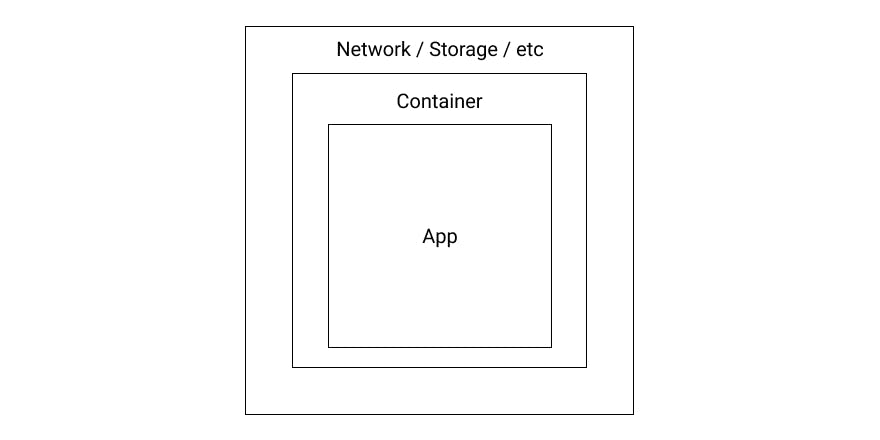
Nearly everything in Kubernetes is an object. Objects are persistent entities within the Kubernetes system. A Pod is one of the most primitive objects Kubernetes can handle and is a fundamental building block. It is used by many other more advanced objects.
A Pod can also contain so-called init-containers. Those containers are run before the actual containers of the Pod are started, and are then shut down again. One of the most common use-cases for an init-container is waiting for the required resources to become available. Many microservices need some sort of connection to a database. That logic can be put into an init-container that polls for a database to be available. As soon as the database is available, the init-container shuts down successfully and the actual container can start.
Why do we need Pods?
As we've already learned, a Pod is a fundamental building block of Kubernetes which doesn't handle raw containers but instead takes containers and always wraps them with a Pod. This design actually has certain advantages. Even if a Pod does only contain one container, it can be seen as an abstraction that can in return be implemented in several ways.
Why? Well, Kubernetes supports multiple runtimes. Some runtimes support Pods themselves, and others don't. No matter what runtime you use, all you see is Pods, and the underlying implementation is basically hidden from you.
The other advantage is that there's always a Pod. Not a Container (A SingleContainerPod) and a Pod (a MultiContainerPod). The amount of containers running doesn't matter anymore, as only Pod handling needs to be implemented by Kubernetes.
And on a user-level, this also is beneficial. All you need to deploy is a Pod. You don't need to deploy a container if there's only one, and a Pod if there are multiple containers. This makes the handling easier for you, and that's a great thing for developer experience.
Creation of a Pod
As long as you have a container at hand that is pushed to a registry accessible for your cluster, you're good to go.
You can take a look at the Pod example spec shown below to get an idea of how it looks.
apiVersion: v1
kind: Pod
metadata:
name: example-app
labels:
app: example-app
version: v1
role: backend
spec:
containers:
- name: user-api
image: my-org/user-api
ports:
- containerPort: 80
volumeMounts:
- mountPath: /volumes/templates
name: templates
livenessProbe:
httpGet:
path: /health
port: 80
httpHeaders:
- name: Liveness
value: check
initialDelaySeconds: 3
periodSeconds: 3
You can send this spec off to your Kubernetes cluster by calling kubectl apply -f pod.yaml and Kubernetes will immediately start with its work.
The control plane components will first take the spec and save it to the object storage (etcd). Another component will then process the spec and check if it already has the image at hand. If not, it will pull it from the registry, and then deploy the Pod to the cluster.
After that, a kubelet on a certain node, which is selected based on information like the resources available and more, is instructed to deploy the Pod and with that the container associated with it.
Three seconds after the Pod was actually started, Kubernetes will try to check if the Pod is actually ready.
After three seconds an HTTP GET request is sent to the HTTP endpoint specified within your Pod template, and on receiving a successful HTTP status code, the Pod will be reported to be alive.
Then finally, your Pod is running and ready to be used!
Every three seconds, Kubernetes will check in with the same endpoint to see if the Pod is still alive. If that request ever fails, Kubernetes will consider the Pod dead, kill it, and then restart it again.
Should you use Pods?
That's an interesting question! You can, of course, use Pods to deploy your applications, but you shouldn't.
Although you can tell Kubernetes to deploy a "raw pod", there are more advanced objects like Deployments, Jobs, or DaemonSets, which offer way more functionality than a basic Pod. And they all use Pods under the hood, next to their advanced functionality.
It's good to know what a Pod is, and how to use it, but in the end, you'll mostly work with other objects. See a Pod as the fundamental building block that it is, and play around with it a little to get used to what you can do with it. But other than that, if you ever think about deploying something to production, better take a look at more advanced workflow objects.
Before you leave
If you like my content, visit me on Twitter, and perhaps you’ll like what you see.